
With the world
passing 10% IPv6 penetration over the weekend,
we see the same old debates coming up again; people claiming IPv6 will
never happen (despite several years now of exponential growth!),
and that if they had only designed it differently, it would have been
all over by now.
In particular, people like to point to a
2002 3 article by D. J. Bernstein,
complete with rants about how Google would never set up useless IPv6
addresses (and then they did that in 2007 I was involved). It's difficult
to understand
exactly what the article proposes since it's heavy on
calling people idiots and light on actual implementation details (as opposed
to when DJB's gotten involved in other fields; e.g. thanks to him we now have
elliptical curve crypto that doesn't suck, even if the
reference implementation was sort of a pain to build), but I will try to
go through it nevertheless and show how I cannot find any way it would work
well in practice.
One thing first, though: Sorry, guys, the ship has sailed. Whatever genius
solution DJB may have thought up that I'm missing, and whatever IPv6's
shortcomings (they're certainly there), IPv6 is what we have. By now, you can not
expect anything else to arise and take over the momentum; we will either live
with IPv6 or die with IPv4.
So, let's see what DJB says. As far as I can see, his primary call is for
a version of IPv6 where the address space is an extension of the IPv4
space. For sake of discussion, let's call that IPv4+ , although it would
share a number of properties with IPv6. In particular, his proposal requires
changing the OS and other software on every single end host out there,
just as IPv6; he readily admits that and outlines how it's done in rough
terms (change all structs, change all configuration files, change all
databases, change all OS APIs, etc.). From what I can see, he also readily
admits that IPv4 and IPv4+ hosts cannot talk to each other, or more clearly,
we cannot start using the extended address space before almost everybody
has IPv4+ capable software. (E.g., quote: Once these software upgrades have been
done on practically every Internet computer, we'll have reached the magic
moment: people can start relying on public IPv6 addresses as replacements for
public IPv4 addresses. )
So, exactly how does the IPv4 address space fit into the IPv4+ address space?
The article doesn't really say anything about this, but I can imagine only
two strategies: Build the IPv4+ space
around the IPv4 space (ie., the IPv4
space occupies a little corner of the IPv4+ space, similar to how v4-mapped
addresses are used within software but not on the wire today, to let
applications do unified treatment of IPv4 addresses as a sort of special IPv6
address), or build it as a
hierarchical extension.
Let's look at the former first; one IPv4 address gives you one IPv4+ addresses.
Somehow this seems to give you all the disadvantages of IPv4
and all the
disadvantages of IPv6. The ISP is not supposed to give you any more IPv4+
addresses (or at least DJB doesn't want to contact his ISP about more also
saying that the fact that automatic address distribution does not change his
argument), so if you have one, you're stuck with one. So you still need NAT.
(DJB talks about proxies , but I guess that the way things evolved, this
either actually means NAT, or it talks about the practice of
application-level proxies such as Squid or SOCKS proxies to reach the
Internet, which really isn't commonplace anymore, so I'll assume for the sake
of discussion it means NAT.)
However, we already
do NAT. The IPv4 crunch happened
despite ubiquitous
NAT everywhere; we're actually pretty empty. So we will need to hand out
IPv4+ addresses at the very least to new deployments, and also probably
reconfigure every site that wants to expand and is out of IPv4 addresses.
( Site here could mean any organizational unit, such as if your neighborhood
gets too many new subscribers for your ISP's local addressing scheme to have
enough addresses for you.)
A much more difficult problem is that we now need to route these addresses on
the wire. Ironically, the least clear part of DJB's plan is step 1, saying
we will extend the format of IP packets to allow 16-byte addresses ; how
exactly will this happen? For this scheme, I can only assume some sort of
IPv4 option that says the stuff in the dstaddr field is just the start and
doesn't make sense as an IPv4 address on its own; here are the remaining 12 bytes
to complete the IPv4+ address . But now your routers need to understand that
format, so you cannot do with only upgrading the end hosts; you also need to
upgrade every single router out there, not just the end hosts. (Note that
many of these do routing in hardware, so you can't just upgrade the software
and call it a day.) And until that's done, you're exactly in the same
situation as with IPv4/IPv6 today; it's incompatible.
I do believe this option is what DJB talks about. However, I fail to see
exactly how it is much better than the IPv6 we got ourselves into; you still
need to upgrade all software on the planet and all routers on the planet.
The benefit is supposedly that a company or user that doesn't care can just
keep doing nothing, but they
do need to care, since they need to upgrade
100% of their stuff to understand IPv4+ before we can start even deploying it
alongside IPv4 (in contrast with IPv6, where we now have lots of experience
in running production networks). The
single benefit is that they won't have
to renumber until they need to grow, at which point they need to anyway.
However, let me also discuss the other possible interpretation, namely that
of the IPv4+ address space being an extension of IPv4, ie. if you have
1.2.3.4 in IPv4, you have 1.2.3.4.x.x.x.x or similar in IPv4+. (DJB's article
mentions 128-bit addresses and not 64-bit, though; we'll get to that in a
moment.) People keep bringing this up, too; it's occasionally been called
BangIP (probably jokingly, as in
this April Fool's joke) due to
the similarity with how explicit mail routing would work before SMTP became
commonplace. I'll use that name, even though others have been proposed.
The main advantage of BangIP is that you can keep your Internet core routing
infrastructure. One way or the other, they will keep seeing IPv4 addresses
and IPv4 packets; you need no new peering arrangements etc.. The exact
details are unclear, though; I've seen people suggest GRE tunneling, ignoring
problems they have through NAT, and I've seen suggestions of IPv4 options
for source/destination addresses, also ignoring that someting as innocious
as setting the ECN bits has been known to break middleboxes left and right.
But let's assume you can pull that off, because your middlebox will almost
certainly need to be the point that decapsulates BangIP anyway and converts
it to IPv4 on the inside, presumably with a 10.0.0.0/8 address space so that
your internal routing can keep using IPv4 without an IPv4+ forklift upgrade.
(Note that you now lose the supposed security benefit of NAT, by the way,
although you could probably encrypt the address.) Of course, your
hosts
will need to support IPv4+ still, and you will need some way of communicating
that you are on the inside of the BangIP boundary. And you will need to know
what the inside is, so that when you communicate on this side, you'll send
IPv4 and not IPv4+. (For a home network with no routing, you could probably
even just do IPv4+ on the inside, although I can imagine complications.)
But like I wrote above, experience has shown us that 32 extra bits isn't
enough. One layer of NAT isn't doing it, we need two. You could imagine
the inter-block routability of BangIP helping a fair bit here (e.g.,
a company with too many machines for 10.0.0.0/8 could probably easily
get more addresses for more external IPv4 addresses, yielding 10.0.0.0/8
blocks), but ultimately, it is a problem that you chop the Internet off
in two distinct halves that work very differently. My ISP will probably
want to use BangIP for itself, meaning I'm on the outside of the core; how
many of those extra bits will they allocate for me? Any at all?
Having multiple levels of bang sounds like pain; effectively we're creating
a variable-length address. Does anyone ever want that? From experience, when
we're creating protocols with variable-length addresses, people just tend to
use the maximum level anyway, so why not design it with 128-bit to begin
with? (The original IP protocol proposals actually had variable-length
addresses, by the way.) So we can create our 32/96 BangIP , where the first
32 bits are for the existing public Internet, and then every IPv4 address
gives you a 2^96 addresses to play with. (In a sense, it reminds me of 6to4,
which never worked very well and is now thankfully dead.)
However, this makes the inside/outside-core problem even worse. I now need
two very different wire protocols coexisting on the Internet; IPv4+ (which
looks like regular IPv4 to the core) for the core, and a sort of
IPv4+-for-the-outside (similar to IPv6) outside it.
If I build a company network, I need to
make sure all of my routers are IPv4+-for-the-outside and talk that, while if I build the
Internet core, I need to make sure all of my connections are IPv4 since
I have no guarantee that I will be routable on the Internet otherwise.
Furthermore, I have a fixed prefix that I cannot really get out of, defined
by my IPv4 address(es). This is called hierarchical routing , and the IPv6
world gave it up relatively early despite it sounding like a great idea at
first, because it makes multihoming a complete pain: If I have an address
1.2.3.4 from ISP A and 5.6.7.8 from ISP B, which one do I use as the first
32 bits of my IPv4+ network if I want it routable on the public Internet?
You could argue that the solution for me is to get an IPv4 PI netblock
(supposedly a /24, since we're not changing the Internet core), but we're
already out of those, which is why we started this thing to begin with.
Furthermore, if the IPv4/IPv4+ boundary is above my immediate connection
to the Internet (say, ISP A doesn't have an IPv4 address, just IPv4+),
I'm pretty hosed; I cannot announce an IPv4 netblock in BGP. The fact that
the Internet runs on largely the same protocol everywhere is a very nice
thing; in contrast, what is described here really
would be a mess!
So, well. I honestly don't think it's as easy to just do extension instead of
alternative when it comes to the address spaces. We'll just need to deal
with the pain and realize that upgrading the equipment and software is the
larger part of the job anyway, and we'll need to do that no matter what
solution we go with.
Congrats on reaching 10%! Now get to work with the remaining 90%.
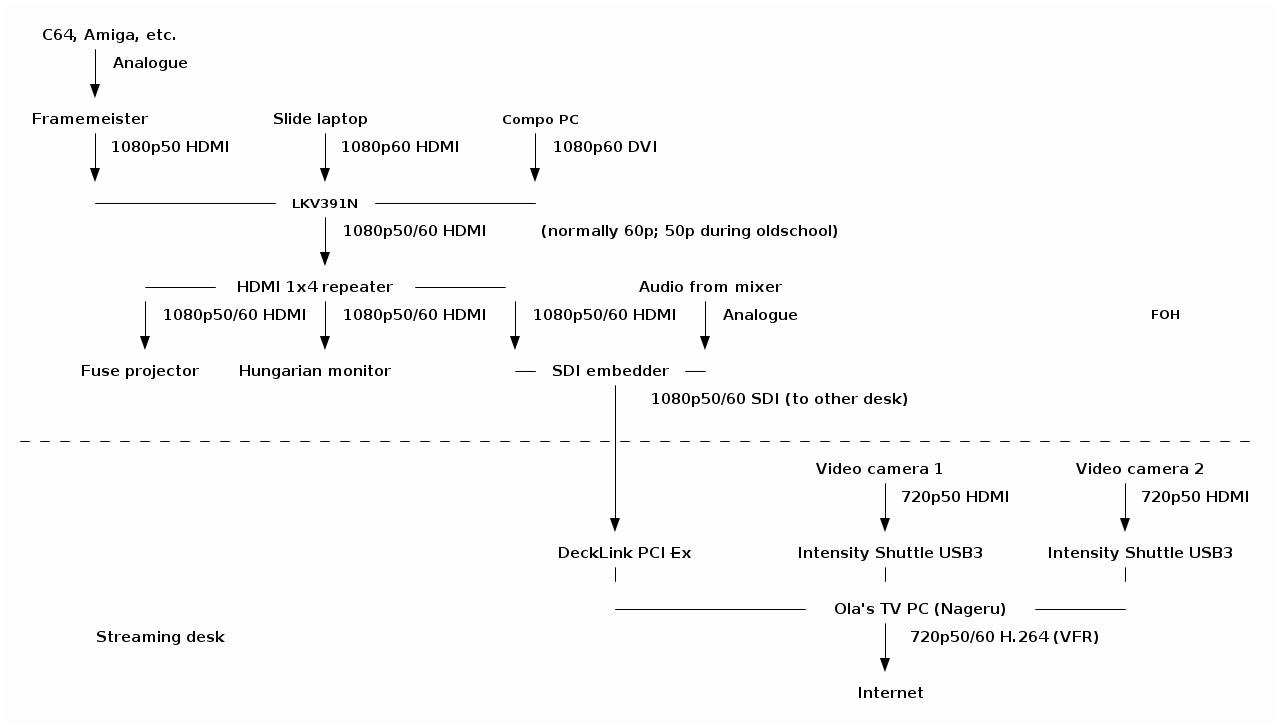 Of course, for me, the really interesting part here is near the end of the
chain, with Nageru, my live video mixer, doing
the stream mixing and encoding. (There's also
Cubemap, the video reflector, but honestly,
I never worry about that anymore. Serving 150 simultaneous clients is just
not something to write home about anymore; the only adjustment I would want
to make would probably be some WebSockets support to be able to deal with iOS
without having to use a secondary HLS stream.) Of course, to make things
even more complicated, the live shader compo needs two different inputs
(the two coders' laptops) live on the bigscreen, which was done with two
video capture cards, text chroma-keyed on top from Chroma, and
OBS, because the guy
controlling the bigscreen has different preferences from me. I would take
his screen in as a dirty feed and then put my own stuff around it, like
this:
Of course, for me, the really interesting part here is near the end of the
chain, with Nageru, my live video mixer, doing
the stream mixing and encoding. (There's also
Cubemap, the video reflector, but honestly,
I never worry about that anymore. Serving 150 simultaneous clients is just
not something to write home about anymore; the only adjustment I would want
to make would probably be some WebSockets support to be able to deal with iOS
without having to use a secondary HLS stream.) Of course, to make things
even more complicated, the live shader compo needs two different inputs
(the two coders' laptops) live on the bigscreen, which was done with two
video capture cards, text chroma-keyed on top from Chroma, and
OBS, because the guy
controlling the bigscreen has different preferences from me. I would take
his screen in as a dirty feed and then put my own stuff around it, like
this:
 (Unfortunately, I forgot to take a screenshot of Nageru itself during this
run.)
Solskogen was the first time I'd really used Nageru in production, and
despite super-extensive testing, there's always something that can go wrong.
And indeed there was: First of all, we discovered that the local Internet
line was reduced from 30/10 to 5/0.5 (which is, frankly, unusable for
streaming video), and after we'd half-way fixed that (we got it to
25/4 or so by prodding the ISP, of which we could reserve about 2 for
video demoscene content is really hard to encode, so I'd prefer a lot
more) Nageru started crashing.
It wasn't even crashes I understood anything of. Generally it seemed like the
NVIDIA drivers were returning GL_OUT_OF_MEMORY on things like creating
mipmaps; it's logical that they'd be allocating memory, but we had 6 GB of
GPU memory and 16 GB of CPU memory, and lots of it was free. (The PC we used for encoding was much,
much faster than what you need to run Nageru smoothly, so we had plenty of
CPU power left to run x264 in, although you can of course always want more.)
It seemed to be mostly related to zoom transitions, so I generally avoided
those and ran that night's compos in a more static fashion.
It wasn't until later that night (or morning, if you will) that I actually
understood the bug (through the godsend of the
NVX_gpu_memory_info
extension, which gave me enough information about the GPU memory state that I
understood I wasn't leaking GPU memory at all); I had set Nageru to lock all of its memory used in RAM,
so that it would never ever get swapped out and lose frames for that reason.
I had set the limit for lockable RAM based on my test setup, with 4 GB of RAM, but this
setup had much more RAM, a 1080p60 input (which uses more RAM, of course)
and a second camera, all of which I hadn't been able to test before, since I
simply didn't have the hardware available. So I wasn't hitting the available
RAM, but I was hitting the amount of RAM that Linux was willing to lock into
memory for me, and at that point, it'd rather return errors on memory
allocations (including the allocations the driver needed to
make for its texture memory backings) than to violate the never swap
contract.
Once I fixed this (by simply increasing the amount of lockable memory in
limits.conf), everything was rock-stable, just like it should be, and I could
turn my attention to the actual production. Often during compos, I don't
really need the mixing power of Nageru (it just shows a single input, albeit
scaled using high-quality Lanczos3 scaling on the GPU to get it down from
1080p60 to 720p60), but since entries come in using different sound levels
(I wanted the stream to conform to EBU R128, which it generally did)
and different platforms expect different audio work (e.g., you wouldn't put a
compressor on an MP3 track that was already mastered, but we did that on e.g.
SID tracks since they have nearly zero ability to control the overall volume),
there was a fair bit of manual audio tweaking during some of the compos.
That, and of course, the live 50/60 Hz switches were a lot of fun: If an
Amiga entry was coming up, we'd 1. fade to a camera, 2. fade in an overlay
saying we were switching to 50 Hz so have patience, 3. set the camera as
master clock (because the bigscreen's clock is going to go away soon), 4.
change the scaler from 60 Hz to 50 Hz (takes two clicks and a bit of
waiting), 5. change the scaler input in Nageru from 1080p60 to 1080p50, 6.
steps 3,2,1 in reverse. Next time, I'll try to make that slightly smoother,
especially as the lack of audio during the switch (it comes in on the
bigscreen SDI feed) tended to confuse viewers.
So, well, that was a lot of fun, and it certainly validated that you can
do a pretty complicated real-life stream with Nageru. I have a long list
of small tweaks I want to make, though; nothing beats actual experience
when it comes to improving processes. :-)
(Unfortunately, I forgot to take a screenshot of Nageru itself during this
run.)
Solskogen was the first time I'd really used Nageru in production, and
despite super-extensive testing, there's always something that can go wrong.
And indeed there was: First of all, we discovered that the local Internet
line was reduced from 30/10 to 5/0.5 (which is, frankly, unusable for
streaming video), and after we'd half-way fixed that (we got it to
25/4 or so by prodding the ISP, of which we could reserve about 2 for
video demoscene content is really hard to encode, so I'd prefer a lot
more) Nageru started crashing.
It wasn't even crashes I understood anything of. Generally it seemed like the
NVIDIA drivers were returning GL_OUT_OF_MEMORY on things like creating
mipmaps; it's logical that they'd be allocating memory, but we had 6 GB of
GPU memory and 16 GB of CPU memory, and lots of it was free. (The PC we used for encoding was much,
much faster than what you need to run Nageru smoothly, so we had plenty of
CPU power left to run x264 in, although you can of course always want more.)
It seemed to be mostly related to zoom transitions, so I generally avoided
those and ran that night's compos in a more static fashion.
It wasn't until later that night (or morning, if you will) that I actually
understood the bug (through the godsend of the
NVX_gpu_memory_info
extension, which gave me enough information about the GPU memory state that I
understood I wasn't leaking GPU memory at all); I had set Nageru to lock all of its memory used in RAM,
so that it would never ever get swapped out and lose frames for that reason.
I had set the limit for lockable RAM based on my test setup, with 4 GB of RAM, but this
setup had much more RAM, a 1080p60 input (which uses more RAM, of course)
and a second camera, all of which I hadn't been able to test before, since I
simply didn't have the hardware available. So I wasn't hitting the available
RAM, but I was hitting the amount of RAM that Linux was willing to lock into
memory for me, and at that point, it'd rather return errors on memory
allocations (including the allocations the driver needed to
make for its texture memory backings) than to violate the never swap
contract.
Once I fixed this (by simply increasing the amount of lockable memory in
limits.conf), everything was rock-stable, just like it should be, and I could
turn my attention to the actual production. Often during compos, I don't
really need the mixing power of Nageru (it just shows a single input, albeit
scaled using high-quality Lanczos3 scaling on the GPU to get it down from
1080p60 to 720p60), but since entries come in using different sound levels
(I wanted the stream to conform to EBU R128, which it generally did)
and different platforms expect different audio work (e.g., you wouldn't put a
compressor on an MP3 track that was already mastered, but we did that on e.g.
SID tracks since they have nearly zero ability to control the overall volume),
there was a fair bit of manual audio tweaking during some of the compos.
That, and of course, the live 50/60 Hz switches were a lot of fun: If an
Amiga entry was coming up, we'd 1. fade to a camera, 2. fade in an overlay
saying we were switching to 50 Hz so have patience, 3. set the camera as
master clock (because the bigscreen's clock is going to go away soon), 4.
change the scaler from 60 Hz to 50 Hz (takes two clicks and a bit of
waiting), 5. change the scaler input in Nageru from 1080p60 to 1080p50, 6.
steps 3,2,1 in reverse. Next time, I'll try to make that slightly smoother,
especially as the lack of audio during the switch (it comes in on the
bigscreen SDI feed) tended to confuse viewers.
So, well, that was a lot of fun, and it certainly validated that you can
do a pretty complicated real-life stream with Nageru. I have a long list
of small tweaks I want to make, though; nothing beats actual experience
when it comes to improving processes. :-)
 My video testing machine has now seemingly accumulated:
My video testing machine has now seemingly accumulated:


 If that's not dramatic enough for you (trust me, you'll notice it when
it's animated as you flicker through the two different fields), here's
an even more high-contrast example (same ordering):
If that's not dramatic enough for you (trust me, you'll notice it when
it's animated as you flicker through the two different fields), here's
an even more high-contrast example (same ordering):


 I guess it's obvious in retrospect what happens; the HF filter picks up
residue from its outer edges, and even if the coefficient is just 0.031
(well, times two; it adds that value from both the previous and next field),
3% the photons of a fully lit pixel (which is what you get when working in
linear light) is actually quite a bit, whereas a 3% gray is only pixel value
8 or so, which is barely visible.
So what am I to make of this? I'm honestly not sure. Maybe it's somehow
related to that these filter values were chosen in 1988, where they were
relatively unlikely to do this in linear light (although if they did it
with analog circuitry, perhaps they could?) and it was tweaked to look good
despite doing the wrong thing. Or maybe I need to change my approach here
entirely.
It always sucks when your fundamental assumptions are challenged, but I
think it shows once again that if you notice something funny in your output,
you really ought to investigate, because you never know how deep the rabbit
hole goes. :-/
I guess it's obvious in retrospect what happens; the HF filter picks up
residue from its outer edges, and even if the coefficient is just 0.031
(well, times two; it adds that value from both the previous and next field),
3% the photons of a fully lit pixel (which is what you get when working in
linear light) is actually quite a bit, whereas a 3% gray is only pixel value
8 or so, which is barely visible.
So what am I to make of this? I'm honestly not sure. Maybe it's somehow
related to that these filter values were chosen in 1988, where they were
relatively unlikely to do this in linear light (although if they did it
with analog circuitry, perhaps they could?) and it was tweaked to look good
despite doing the wrong thing. Or maybe I need to change my approach here
entirely.
It always sucks when your fundamental assumptions are challenged, but I
think it shows once again that if you notice something funny in your output,
you really ought to investigate, because you never know how deep the rabbit
hole goes. :-/